Ketika Robot Mulai ‘Ngulang’ Omong Kosong: Jurus DPO Bikin AI Nggak Nyebelin Lagi!
Pernahkah kamu merasa frustrasi ketika robot yang katanya ‘cerdas’ itu malah sibuk mengulang-ulang hal yang sama, mirip kaset kusut? Fenomena ini, yang dikenal sebagai ‘degenerasi teks’, adalah biang kerok kegagalan AI di dunia nyata. Tapi tenang, para Majikan AI, ada kabar baik! Sebuah metode baru bernama Direct Preference Optimization (DPO) kini hadir, tidak hanya sebagai penjinak chatbot yang suka berhalusinasi, tapi juga sebagai solusi ampuh untuk membuat robot bekerja lebih akal sehat, terutama di tugas-tugas terstruktur seperti OCR (Optical Character Recognition).
Mengapa Robot Sering ‘Ngulang’ Omong Kosong?
Model-model AI, secerdas apapun, seringkali tersandung pada lubang yang sama: degenerasi teks. Bayangkan asisten rumah tanggamu yang rajin, tapi tiba-tiba terjebak dalam lingkaran membersihkan sudut yang sama berkali-kali. Begitulah AI ketika degenerasi menyerang; ia mengulang-ulang pola atau frasa tanpa henti, bukannya menyelesaikan tugas. Studi dari Dharma-AI pada model OCR mereka menunjukkan bahwa tingkat degenerasi ini bisa mencapai lebih dari 33% pada model “polosan” dan masih sulit diatasi sepenuhnya hanya dengan Supervised Fine-Tuning (SFT).
SFT memang membantu, tapi ibarat mengajari anak kecil membaca kata demi kata, tanpa peduli apakah kalimatnya masuk akal secara keseluruhan. SFT mengoptimalkan keluaran yang benar, namun buta terhadap ‘kebiasaan buruk’ seperti pengulangan. Ia tak punya ‘mata’ untuk melihat output secara utuh dan memberikan sanksi pada kegagalan di tingkat ‘kalimat’. Oleh karena itu, tingkat kegagalan seringkali stagnan di level yang tidak bisa ditoleransi untuk pekerjaan produksi. Kondisi ini serupa dengan fenomena ‘halusinasi’ yang sering terjadi pada chatbot. Jika kamu ingin tahu lebih lanjut mengapa robot sering ngawur dan cara mengatasinya, simak artikel kami tentang Membedah ‘Dukun’ AI: Kenapa Chatbot Kesehatan Masih Sering ‘Halusinasi’.
DPO: Guru Privat yang Lebih Tegas untuk Robot
Di sinilah Direct Preference Optimization (DPO) masuk sebagai guru privat yang lebih tegas. DPO tidak sekadar menatap token demi token, tapi mengevaluasi seluruh hasil kerja si robot. Filosofinya sederhana: kalau ada hasil yang bagus, pilih itu. Kalau ada yang ngaco, tolak mentah-mentah! Ibarat kamu meminta asisten membuat laporan, kalau laporannya cuma mengulang judul berkali-kali, tentu langsung dibuang, kan? DPO melakukan hal serupa pada algoritma, menjadikan kegagalan robot sebagai pelajaran berharga untuk tidak mengulangi kebodohan yang sama.
Desain Jenius: Memanfaatkan Kegagalan Robot Sebagai Pelajaran
Inovasi dari tim Dharma-AI melalui DharmaOCR sungguh cerdik. Alih-alih membuang hasil ‘ngaco’ sebagai sampah data, mereka justru menjadikannya pasangan penolakan (rejection pairs) untuk DPO. Ini seperti memanfaatkan kesalahan asistenmu sebagai studi kasus, ‘Ini lho, jangan sampai terulang lagi!’. Output yang benar dijadikan ‘pasangan pilihan’, dan output yang degenerasi jadi ‘pasangan penolakan’. Proses ini mirip dengan seorang Majikan yang tegas, tahu mana yang layak dipuji dan mana yang harus dibetulkan, bukan sekadar membiarkan robot terus berhalusinasi. DharmaOCR sendiri adalah model spesialis yang menunjukkan bagaimana AI dapat dilatih untuk tugas-tugas spesifik, seperti persepsi dokumen yang mendalam. Untuk memahami lebih jauh potensi AI dalam tugas visual, baca juga Falcon Perception & OCR: Saat Algoritma Punya ‘Mata Elang’.
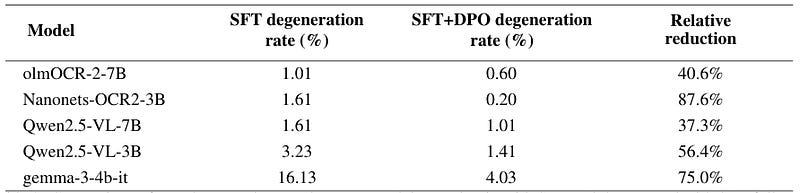
DPO mengajarkan model untuk menjauhi pola kegagalan spesifik, seperti pengulangan. Hal ini berbeda dengan SFT yang hanya mencoba mendekatkan model ke jawaban benar, tanpa secara eksplisit menghukum perilaku yang tidak diinginkan. Hasilnya? Penurunan tingkat degenerasi yang konsisten dan signifikan.
Baca juga artikel menarik lainnya di kategori Update Algoritma.
Konsisten di Berbagai Model: Bahkan Saat SFT Malah Bikin Kacau!
Yang menarik, metode ini berhasil konsisten di lima keluarga model berbeda, dengan rata-rata penurunan degenerasi 59.4% dibandingkan hanya dengan SFT. Bahkan ada kasus seperti Qwen2.5-VL-3B, yang setelah SFT malah makin sering ‘ngulang’ omong kosong karena lebih berani mencoba tugas kompleks. Tapi setelah disuntik DPO, model tersebut langsung ‘tahu diri’ dan tingkat degenerasinya anjlok. Ini membuktikan bahwa SFT dan DPO adalah dua jenis ‘pendidikan’ yang berbeda untuk robot. SFT mengajarkan cara melakukan tugas, sementara DPO mengajarkan cara tidak melakukan kesalahan fatal yang spesifik. Mirip anak sekolah, SFT itu guru mata pelajaran, DPO itu guru Bimbingan Konseling yang fokus memperbaiki perilaku buruk.
Sebagai Majikan AI yang cerdas, kemampuan untuk memahami dan mengarahkan perilaku AI adalah kunci. Jangan sampai robot kesayanganmu hanya jago di atas kertas, tapi ‘halusinasi’ di dunia nyata. Untuk mengendalikan AI agar sesuai dengan keinginanmu dan tidak jadi ‘babu’ teknologi, kamu bisa mulai dengan mempelajari lebih dalam di AI Master. Apalagi jika kamu banyak berurusan dengan tugas visual seperti OCR, menguasai teknologi visual AI adalah sebuah keharusan agar hasil ekstraksi datamu presisi dan bebas dari ‘ngulang’ omong kosong. Kamu bisa mengasahnya di Belajar AI | Visual AI.
Kesimpulan: Majikan yang Akal Sehat, Bukan Babu Robot
Pada akhirnya, DPO membuktikan bahwa Majikan yang cerdas tidak hanya mendidik AI dengan iming-iming hasil baik, tapi juga dengan ancaman nyata terhadap kegagalan. Dengan mengubah kesalahan menjadi pelajaran, kita memastikan robot tetap berada di jalur yang benar. Ingat, robot hanyalah tumpukan kode mati tanpa akal yang punya perintah. Kaulah Majikan yang punya akal, yang menekan tombol, dan yang mendikte masa depan mereka.
Sumber Berita:
Artikel ini dirangkum dari sumber asli di “Direct Preference Optimization Beyond Chatbots”
Gambar oleh: Dharma-AI via Hugging Face
Dan ingat, kalau robot sudah bisa buat kopi sendiri, pastikan gulanya nggak kebanyakan, ya!