NVIDIA Luncurkan Nemotron-Personas-Brazil: Robot Makin ‘Brazil Banget’, Akal Majikan Harus Lebih Lokal!
Akhirnya, para majikan AI di seluruh dunia, khususnya di Brazil, bisa bernapas lega. NVIDIA, raksasa chip yang kini juga merambah ke ranah data, baru saja meluncurkan Nemotron-Personas-Brazil. Ini bukan sekadar dataset biasa, melainkan koleksi 6 juta persona sintetis yang dirancang khusus agar AI bisa “berbicara” dan “berpikir” seperti orang Brazil sungguhan. Pertanyaannya, bagaimana kita sebagai majikan bisa memanfaatkan robot yang makin lokal ini?
Di dunia AI yang didominasi bahasa Inggris, mencari data pelatihan berkualitas tinggi dengan nuansa lokal adalah tantangan berat. Brazil, dengan lebih dari 200 juta penduduk yang tersebar di berbagai wilayah dan budaya, adalah contoh sempurna dari kebutuhan tersebut. Nemotron-Personas-Brazil hadir sebagai jawaban, menjembatani kesenjangan ini dengan data yang secara statistik berakar pada sensus resmi dan data tenaga kerja dari Brazilian Institute of Geography and Statistics (IBGE).
Ketika AI Belajar Adab dan Budaya Lokal
Yang paling menarik, setiap persona dalam dataset ini sejajar dengan distribusi demografi, geografis, dan pekerjaan yang nyata—tapi jangan salah, tidak ada satu pun orang sungguhan yang terwakili. Semua murni sintetis. Ini adalah langkah maju yang cerdas untuk memastikan privasi, sembari tetap memberikan AI “rasa” lokal yang otentik. Sebuah konsep yang juga pernah NVIDIA terapkan saat merilis data AI untuk Singapura, menunjukkan komitmen mereka pada lokalisasi AI.
Dataset ini meliputi:
- 6 juta persona (1 juta catatan x 6 persona masing-masing).
- Total ~1,4 miliar token, termasuk ~450 juta token persona.
- 20 field per catatan: 6 field persona + 14 field kontekstual berdasarkan statistik resmi.
- Cakupan geografis penuh: 26 negara bagian Brazil + Distrik Federal.
- ~457 ribu nama Portugis unik.
- Lebih dari 1.500 kategori pekerjaan yang merefleksikan angkatan kerja Brazil.
- Berbagai tipe persona: profesional, olahraga, seni, perjalanan, dan banyak lagi.
Setiap persona ditulis dalam bahasa Portugis Brazil yang alami, lengkap dengan latar belakang budaya, keahlian, tujuan, hobi, dan minat. Ini adalah bukti bahwa meski AI bisa sangat cerdas dalam memproses data, ia masih butuh kendali dan panduan dari Majikan AI untuk memahami nuansa yang rumit seperti budaya dan adab. AI memang bisa belajar “menirukan”, tapi tidak bisa “merasakan”.
Dapur Rahasia Pembuatan Persona Sintetis NVIDIA
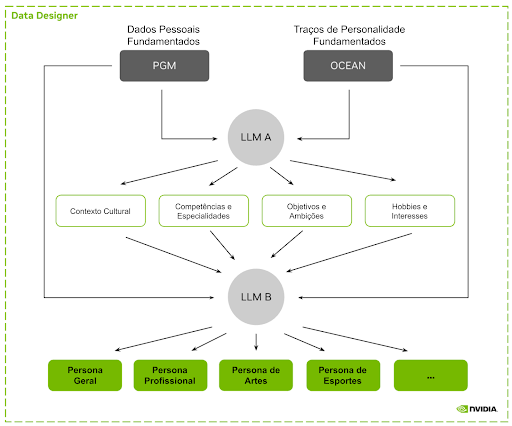
Nemotron-Personas-Brazil dibangun menggunakan NeMo Data Designer, sistem AI gabungan NVIDIA untuk generasi data sintetis. Pipeline ini mendukung mekanisme generasi, validasi, dan percobaan ulang terstruktur yang diperlukan untuk menghasilkan dataset berskala besar yang sadar populasi.
Komponen utamanya termasuk:
- Probabilistic Graphical Model (Apache-2.0) untuk landasan statistik.
- GPT-OSS-120B (Apache-2.0) untuk generasi narasi dalam bahasa Portugis Brazil.
Versi yang diperluas dari Nemotron-Personas-Brazil akan tersedia langsung di NeMo Data Designer, memungkinkan pengembang untuk membuat, menyaring, dan memperluas persona Portugis Brazil sebagai bagian dari pipeline data sintetis mereka sendiri. Ini menunjukkan bagaimana NVIDIA terus membangun infrastruktur AI yang kokoh.
Peningkatan Konteks Budaya:
Untuk menangkap keragaman sosio-demografi dan geografis populasi Brazil, Nemotron-Personas-Brazil memanfaatkan data sensus penduduk dan tenaga kerja yang diterbitkan oleh Brazilian Institute of Geography and Statistics (IBGE).
- Geografi – Persona terikat pada tingkat negara bagian dan kota, mencerminkan variasi regional di lima makro-wilayah Brazil.
- Pekerjaan – Meluas dari jabatan pekerjaan hingga mencakup keahlian, spesialisasi, dan jalur karier, termasuk mikro-pengusaha dan perdagangan regional.
- Tahapan Hidup – Menggabungkan status pelajar, pengangguran, dan pensiun untuk mencerminkan dinamika populasi nyata.
- Ciri-ciri Budaya – Persona bahasa alami menangkap norma sosial Brazil, minat, dan dimensi gaya hidup seperti seni, olahraga, dan perjalanan.
- Fidelitas Bahasa – Semua persona ditulis dalam bahasa Portugis Brazil alami, mencerminkan konvensi penamaan lokal dan gaya komunikasi.
Hasilnya adalah dataset yang berbasis statistik, representatif secara budaya, dan sepenuhnya sintetis. Ini penting karena AI, sepintar apapun, tidak bisa menciptakan konteks budaya yang kaya ini dari nol. Ia butuh data yang “ditanam” oleh akal manusia agar tidak berakhir menjadi robot yang canggung dan kurang piknik.
Privasi Sejak Desain (Private By Design):
Dataset ini tidak mengandung informasi identitas pribadi apa pun. Meskipun NVIDIA menggunakan distribusi usia, nama, dan pekerjaan dari sumber publik resmi di dunia nyata, tidak ada yang terikat pada orang sungguhan, hidup atau mati. Setiap persona sepenuhnya sintetis, jadi kita bisa melatih AI berdasarkan pola budaya otentik tanpa mengorbankan privasi.
Baca juga artikel menarik lainnya di kategori Sidang Bot.
Untuk Siapa Data Ini? Aplikasi AI Praktis
Nemotron-Personas-Brazil dirancang terutama untuk para pengembang dan peneliti Brazil yang membangun sistem AI berdaulat (sovereign AI). Dengan menyediakan data berkualitas tinggi dan representatif secara populasi dalam bahasa Portugis Brazil, dataset ini mengisi celah yang ditinggalkan oleh korpus pelatihan berbahasa Inggris yang dominan. Pengembang global juga dapat memanfaatkan dataset ini untuk meningkatkan kinerja model dan keselarasan dalam konteks budaya dan linguistik Brazil.
Aplikasi praktisnya meliputi:
- Percakapan Multi-turn: Gunakan persona sebagai benih untuk menghasilkan dataset dialog otentik.
- Pelatihan Spesifik Domain: Bangun asisten AI yang sadar budaya.
- Pengujian Bias & Keadilan: Evaluasi kinerja model di seluruh populasi pedesaan vs. perkotaan, kelompok usia, dan tingkat pendidikan—memastikan AI Anda bekerja secara adil di semua segmen masyarakat Brazil.
Pada titik ini, perlu diingat bahwa meski AI bisa membantu mengidentifikasi bias, keputusan akhir tentang apa itu “adil” tetap berada di tangan majikan manusia. AI hanyalah alat cermin, yang merefleksikan bias dalam data jika kita tidak hati-hati. Akal sehat kita, sang majikan, harus selalu menjadi filter utama.
Mengapa Ini Penting?
Para pembangun model AI telah lama kesulitan mengakses data pelatihan yang beragam dan berkualitas tinggi yang mencerminkan populasi dunia nyata. Dataset proprietary mendominasi AI perusahaan, menciptakan hambatan bagi peneliti, startup, dan pengembang di wilayah yang kurang terwakili.
- Keberagaman Data: Mencegah pelatihan yang sempit dan model collapse dengan merefleksikan spektrum populasi Brazil secara penuh.
- Keaslian Budaya: Mengurangi ketergantungan pada dataset yang berpusat pada Barat dan mendukung pengembangan AI berdaulat.
- Preservasi Privasi: Dirancang untuk memenuhi persyaratan perlindungan data Brazil dan standar tata kelola AI yang berkembang.
Dengan merilis Nemotron-Personas-Brazil di bawah lisensi CC BY 4.0, NVIDIA mendemokratisasi akses ke data sintetis tingkat perusahaan—memungkinkan siapa saja untuk membangun AI yang otentik secara budaya tanpa hambatan biaya, masalah privasi, atau geografi. Ini adalah langkah maju yang besar, namun tetap, tanpa manusia menekan tombol “mulai” dan “berhenti”, robot-robot ini hanyalah tumpukan kode yang menunggu perintah. Ingat, Majikan AI yang cerdas tahu cara memberi perintah yang tidak bisa dibantah.
Mulai Membangun dengan Nemotron-Personas-Brazil
Kamu bisa memuat dataset ini langsung dari Hugging Face:
from datasets import load_dataset
dataset = load_dataset("nvidia/nemotron-personas-brazil")
Tertarik mempelajari lebih lanjut tentang produk data terbuka NVIDIA, atau ingin berkolaborasi dalam merancang dataset masa depan? Bergabunglah dalam percakapan di Discord NVIDIA.
Pada akhirnya, sehebat apapun Nemotron-Personas-Brazil mencerminkan realitas, ia tetaplah kumpulan kode dan angka. Tanpa akal sehat dan bimbingan majikan manusia, AI hanyalah boneka data yang tak punya jiwa. Ngomong-ngomong, kucing saya kemarin mencoba membayar tagihan listrik dengan daun kering. Masih butuh banyak training data sepertinya.
Sumber Berita: Artikel ini dirangkum dari sumber asli di “Nemotron-Personas-Brazil: Co-Designed Data for Sovereign AI”.
Gambar oleh: TechCrunch Archive via Hugging Face