NVIDIA NeMo AutoModel: Cara Cerdas “Majikan” Melatih AI Raksasa Tanpa Bikin GPU Meledak
Melihat perkembangan kecerdasan buatan saat ini sering kali membuat kita geleng-geleng kepala. Bukan karena sistem ini terlampau cerdas, melainkan karena kerakusannya terhadap daya komputasi yang makin tidak masuk akal. Mengoperasikan model bahasa besar mirip seperti memiliki asisten rumah tangga yang luar biasa rajin, tetapi dia menolak bekerja jika tidak disediakan dapur sekelas restoran bintang lima lengkap dengan pasokan listrik satu kecamatan. Beruntung bagi kita para majikan yang memiliki akal, para insinyur di luar sana terus memutar otak agar asisten kaku ini bisa bekerja lebih efisien tanpa harus membuat tagihan listrik kita setara harga satu unit apartemen.
Langkah terbaru datang dari kolaborasi terselubung antara raksasa chip NVIDIA dan ekosistem open-source Hugging Face. Mereka merilis NVIDIA NeMo AutoModel, sebuah pustaka (library) terbuka yang dirancang khusus untuk mempercepat proses tuning model-model Mixture-of-Experts (MoE) yang terkenal rakus memori. Kabar baiknya? Anda tidak perlu menulis ulang ribuan baris kode rumit yang bikin pusing kepala. Cukup ganti satu baris impor kode, dan biarkan sistem bekerja lebih cepat di bawah kendali mutlak Anda.
Sebagai majikan yang bijak, kita harus paham bahwa AI hanyalah tumpukan kode mati tanpa optimasi yang tepat. Penemuan ini membuktikan bahwa kendali efisiensi mutlak tetap berada di tangan manusia yang tahu cara memencet tombol yang benar.
Analisis Mendalam
Mari kita bedah apa yang sebenarnya terjadi di balik kap mesin teknologi teranyar ini. NVIDIA NeMo AutoModel dirancang untuk berjalan mulus di atas Hugging Face Transformers v5. Versi v5 ini sendiri sebenarnya sudah membawa bekal bagus untuk arsitektur MoE—seperti backend ahli (expert backends), pemuatan bobot dinamis (dynamic weight loading), dan eksekusi terdistribusi. Namun, NVIDIA tampaknya merasa optimasi tersebut masih “kurang piknik” untuk menangani model skala monster.
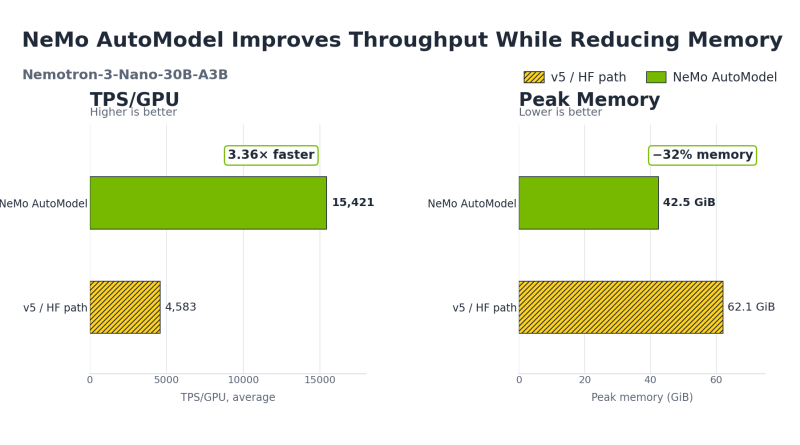
Di sinilah NeMo AutoModel masuk dengan membawa tiga senjata andalan: Expert Parallelism (EP), dispatch all-to-all yang digabungkan lewat DeepEP, dan kernel TransformerEngine (TE). Kombinasi maut ini menghasilkan lompatan performa yang luar biasa kasar: throughput pelatihan 3,4 hingga 3,7 kali lebih tinggi dan penghematan memori GPU sebesar 29 hingga 32 persen dibandingkan dengan Transformers v5 murni. Semuanya dinikmati lewat API from_pretrained() yang sama persis dengan yang biasa Anda gunakan.
Data konkret menunjukkan keperkasaan sistem ini saat menguji model skala gigantik seperti Nemotron 3 Ultra 550B A55B menggunakan 128 GPU H100 (16 node). Pada pengujian tersebut, Transformers v5 murni langsung menyerah dan mengalami out-of-memory (OOM). Sementara itu, NeMo AutoModel dengan konfigurasi EP=64 melenggang mulus menghasilkan throughput rata-rata 815 TPS/GPU dan memuncak pada penggunaan memori hanya 58,2 GiB. Untuk model yang lebih “ramah anggaran” seperti Qwen3-30B-A3B dan Nemotron 3 Nano 30B, peningkatan kecepatannya bahkan mencapai lebih dari tiga kali lipat.
Baca juga artikel menarik lainnya di kategori Update Algoritma.
Batasan Sistem
Namun, sebelum Anda buru-buru memuja alat baru dari NVIDIA ini, mari kita letakkan kaki kembali ke bumi. Kehebatan 3,7 kali lipat ini bukanlah keajaiban magis di mana AI tiba-tiba menemukan cara berpikir baru yang revolusioner. Ini murni masalah manajemen lalu lintas data. AI pada dasarnya adalah pekerja kaku yang tidak tahu cara mengatur mejanya sendiri. Tanpa instruksi parallelism yang dirancang oleh otak manusia, sistem ini akan terus-menerus menabrak dinding batas memori fisik GPU Anda.
Ada satu detail menarik dalam pengujian performa ini: optimasi NeMo AutoModel sangat bergantung pada apa yang disebut sebagai balanced routing gate. Sederhananya, ini adalah fitur yang memaksa token-token data didistribusikan secara merata ke seluruh “ahli” (experts) digital di dalam model. Masalahnya, di dunia nyata, data yang masuk dari pengguna tidak pernah seimbang. Manusia kerap memberikan instruksi yang acak, membingungkan, dan tidak terduga. Ketika beban kerja menjadi tidak seimbang, efisiensi sistem ini akan menurun drastis.
Di sinilah insting manusia tetap memegang kendali mutlak. Kecerdasan buatan tidak bisa mendeteksi kapan distribusi bebannya mulai timpang secara logis; ia hanya mengeksekusi angka-angka matematis. Diperlukan pengawasan jeli dari seorang insinyur manusia untuk memantau hilangnya efisiensi ini dan melakukan penyesuaian parameter secara manual. Tanpa pengawasan kita, AI ini hanyalah mesin jet mahal yang berjalan berputar-putar di tempat parkir.
Dampak Masa Depan
Rilisnya NVIDIA NeMo AutoModel ini dipastikan akan memanaskan persaingan di tingkat infrastruktur kecerdasan buatan. Langkah NVIDIA memperluas kompatibilitas dengan ekosistem Hugging Face menunjukkan bahwa mereka ingin mengunci para pengembang di dalam lingkaran perangkat keras mereka. Dengan membuat model-model open-source berjalan sangat cepat di GPU mereka menggunakan pustaka NeMo, NVIDIA secara tidak langsung menegaskan bahwa untuk hasil terbaik, Anda harus tetap menyewa atau membeli silikon hijau milik mereka.
Bagi para pelaku bisnis dan startup, teknologi ini memangkas biaya iterasi model secara signifikan. Fleksibilitas format penyimpanan yang kompatibel secara bolak-balik (reversible conversion) juga memudahkan model yang sudah di-tune untuk langsung dideploy ke framework inferensi populer seperti vLLM atau SGLang. Ini mempercepat waktu rilis produk ke pasar tanpa harus mengorbankan anggaran operasional yang berharga.
Kesimpulan
Pada akhirnya, NVIDIA NeMo AutoModel hanyalah alat bantu akselerasi yang sangat efisien, bukan pengganti esensi kreativitas manusia. Ia mempercepat waktu tunggu kita, menghemat pengeluaran GPU kita, dan mencegah memori sistem mengalami “gegar otak”. Namun, ingatlah bahwa tanpa arahan taktis, data berkualitas yang kita kurasi, dan keputusan manusia untuk menekan tombol “jalankan”, baris-baris kode optimasi supercepat ini hanyalah deretan angka nol dan satu yang membeku di dalam server dingin.
Hebat memang bisa melatih AI 550 miliar parameter tanpa bikin GPU meledak, tapi tetap saja sistem canggih ini tidak bisa membantu Anda menemukan di mana kunci motor yang Anda letakkan tadi pagi.
Artikel ini dirangkum dari sumber asli di “Hugging Face”.
Gambar oleh: NVIDIA via TechCrunch