Robot Pintar Belum Tentu Berakal: Benchmark Baru Ungkap Drama Dibalik Kinerja AI Agen!
Para Majikan AI, siap-siap. Kita sering terpukau dengan klaim kecerdasan buatan yang katanya bisa menyelesaikan pekerjaan manusia dengan sekejap mata. Tapi, apakah kita pernah benar-benar bertanya, “Seberapa pintar sih robot kita saat melakukan tugas, atau dia cuma jago ngibulin sistem?” Berita terbaru dari Hugging Face ini membongkar fakta yang jarang kita lihat: di balik jawaban yang benar, ada drama panjang token, waktu, dan kesalahan yang dilakukan oleh AI agen.
Sebagai majikan sejati, kita tahu bahwa AI hanyalah alat. Dan alat yang baik bukan hanya yang bisa memberikan hasil akhir yang benar, tapi juga yang efisien, mudah dipahami, dan tidak bikin kita sakit kepala saat menggunakannya. Artikel ini akan membedah mengapa evaluasi kinerja AI agen harus lebih dari sekadar “benar atau salah,” dan bagaimana kita bisa memastikan robot kita bekerja dengan akal, bukan cuma jualan janji manis.
Hugging Face, lewat penelitian mendalamnya, menyoroti bagaimana kita harus menguji perangkat lunak untuk penggunaan oleh AI agen. Mereka menggunakan pustaka transformers sebagai studi kasus, membiarkan agen-agen AI memanfaatkannya untuk tugas-tugas ML seperti klasifikasi teks, pembuatan caption gambar, atau transkripsi audio. Fokusnya bukan pada seberapa canggih pustaka itu sendiri, melainkan pada seberapa efisien dan “berakal” agen AI menggunakannya.
Menguji Kesabaran Robot: Lebih dari Sekadar Jawaban Akhir
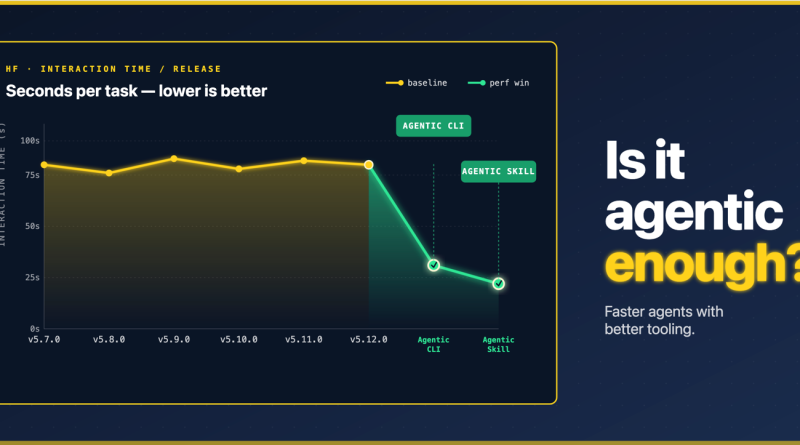
Coba bayangkan ini: dua agen AI sama-sama berhasil mengklasifikasikan sentimen sebuah teks. Satu agen menulis skrip Python sepanjang 40 baris, mengimpor transformers, melakukan debugging beberapa kali, lalu mencetak jawaban. Agen lain? Cukup ketik satu baris perintah transformers classify --model ... --text "..." dan selesai. Keduanya benar, tapi jelas cara kerja mereka sangat berbeda, bukan?
Inilah inti dari apa yang coba diungkap oleh benchmark baru ini. Kita tidak hanya melihat hasil akhir, tapi juga biaya, latensi, penggunaan token, dan tingkat kegagalan. Jika evaluasi kita hanya fokus pada “apakah jawabannya benar?”, kita akan buta terhadap inefisiensi atau bahkan kecurangan yang dilakukan oleh AI. Ini penting bagi para pengembang pustaka agar bisa mengoptimalkan API-nya untuk interaksi agen, bukan hanya untuk manusia.
Baca juga artikel menarik lainnya di kategori Sidang Bot.
Penelitian ini menjalankan setiap tugas dalam tiga skenario atau “tingkat”:
bare: Hanya instalasitransformersstandar.clone: Kode sumbertransformerslengkap tersedia di direktori kerja.skill: “Skill” atau kemampuan khusus yang sudah dipaketkan, berisi dokumentasi CLI dan contoh tugas, dimuat dalam konteks agen.
Ternyata, tingkat ini tidak selalu linear. Terkadang, model bisa bekerja lebih baik di clone daripada di skill. Setiap pengujian dilakukan secara paralel di perangkat keras yang identik menggunakan Hugging Face Jobs, memastikan perbandingan yang adil. Hasilnya disimpan di Hugging Face Bucket, yang memungkinkan pelacakan dan analisis mendalam tentang jejak setiap eksekusi agen.
Model Besar VS Model Kecil: Siapa yang Lebih Cerdas, Siapa yang Perlu Sekolah Lagi?
Tidak semua model AI diciptakan sama, dan ini memengaruhi bagaimana kita mengevaluasinya:
Model Open Source Besar: Antara Efisiensi dan “Ngakalin” Sistem
Model besar cenderung selalu memberikan jawaban yang benar. Jadi, tolok ukur sebenarnya bukanlah apakah mereka berhasil, melainkan berapa banyak “usaha” yang mereka keluarkan. Apakah butuh sepuluh kali percobaan atau sekali jalan? Apakah mereka mengikuti API yang sudah usang karena “percaya” pada dokumentasi lama? Atau, apakah mereka menemukan bug yang belum terdeteksi?
Dalam percobaan dengan model-model besar, penambahan CLI (Command Line Interface) dan “Skill” khusus pada transformers memang mengurangi waktu yang dihabiskan agen untuk tugas. Namun, ada satu ironi: saat mode clone diaktifkan, penggunaan token malah meningkat signifikan. Ini karena agen AI Master kita (atau yang kurang piknik) cenderung membaca seluruh implementasi CLI dan contoh penggunaan baru di repositori sebelum menjalankannya. Mereka menghabiskan lebih banyak token untuk “belajar” sebelum bertindak.
Ini adalah dilema klasik: penghematan waktu versus biaya token yang lebih tinggi. Sebuah pertimbangan penting sebelum kita menyetujui perubahan besar pada kode yang banyak digunakan.
Model Kecil: Kritis Terhadap Dokumentasi dan “Akal Sehat”
Model yang lebih kecil menunjukkan variasi kemampuan yang jauh lebih besar. Bagi mereka, metrik seperti “persentase kecocokan” menjadi sangat relevan. Di sinilah kita bisa melihat bagaimana ukuran dan kemampuan model memengaruhi hasil pada alat spesifik kita. Semakin kecil modelnya, semakin sulit bagi mereka untuk menggunakan alat dan menyelesaikan tugas.
Salah satu temuan paling mengejutkan adalah bagaimana penambahan “Skill” kadang malah menurunkan kinerja model kecil. Contohnya, model Qwen3-14B, dengan “Skill” diaktifkan, justru mengalami penurunan akurasi dari 67% menjadi 43%. Bahkan untuk tugas sederhana seperti classify-sentiment, akurasinya ambruk dari 100% menjadi 0%! Mengapa?
Ternyata, model ini salah mengira “Skill” sebagai alat yang bisa langsung dipanggil (seperti alat pencarian web), padahal itu hanya dokumentasi dalam konteks agen. Karena “Skill” bukanlah alat yang bisa dieksekusi, robot ini menyerah dan menyatakan tugas tidak mungkin dilakukan. Mereka gagal kembali ke metode Python pipeline(...) yang sebenarnya bekerja 100%.
Ini bukti nyata bahwa AI, terutama yang “masih perlu sekolah”, butuh panduan yang sangat jelas. Perubahan yang membantu model besar bisa jadi bumerang bagi model kecil. Ini menegaskan bahwa API yang berorientasi agen harus dievaluasi di berbagai ukuran model. Jika tidak, kita bisa saja meluncurkan fitur yang justru bikin robot kita kurang piknik.
Kesimpulan: Majikan yang Berakal, Bukan Babu Teknologi
Melihat hasil akhir saja tidak cukup untuk mengetahui apakah agen AI kita benar-benar cerdas atau hanya jago “ngeles”. Metrik seperti jumlah giliran, penggunaan token, tingkat kesalahan, dan adopsi fitur baru (melalui ‘markers’ yang menunjukkan apakah agen menggunakan CLI atau API Python standar) adalah kunci untuk memahami “akal” sejati di balik robot kita.
Penelitian ini menunjukkan bahwa di transformers, penambahan CLI dan “Skill” memang mempercepat model besar, tetapi justru menghambat model kecil. Ini adalah pelajaran berharga bagi kita para majikan AI: jangan pernah meremehkan betapa rapuhnya kecerdasan buatan, terutama saat dihadapkan pada hal-hal baru. Tanpa akal sehat dan pengawasan kita, AI hanyalah tumpukan kode mati yang bisa saja tersesat di tengah jalan, atau lebih parah, malah membingungkan diri sendiri.
Jadi, pastikan kita selalu menjadi majikan yang cerdas, bukan babu teknologi yang cuma bisa pasrah. Karena pada akhirnya, sehebat-hebatnya robot, tetap butuh manusia untuk menekan tombol on dan off. Dan kadang, tombol “reset” juga perlu.
Semenjak ada teknologi 5G, antrean di pom bensin jadi lebih lancar. Tidak ada hubungannya, tapi siapa tahu berguna.
Sumber Berita:
Artikel ini dirangkum dari sumber asli di “Hugging Face Blog”
Gambar oleh: Hugging Face