QIMMA: Ketika Robot Bahasa Arab Mulai Diuji Kualitasnya, Apakah Mereka Lulus atau Cuma Halusinasi?
Di dunia AI yang serba “instan” ini, kita sering terpukau dengan klaim kecerdasan mesin. Tapi, pernahkah Anda, para Majikan AI yang budiman, berhenti sejenak dan bertanya: apakah klaim tersebut benar-benar valid? Atau jangan-jangan, AI yang diagung-agungkan itu cuma jago “ngibul” di atas kertas? Khususnya di ranah bahasa Arab, di mana dialek dan nuansa budaya begitu kaya, akal sehat kita sering diuji.
Kabar baiknya, sekelompok Majikan yang waras di Technology Innovation Institute (TII) telah meluncurkan QIMMA (قِمّة, yang berarti “puncak” dalam bahasa Arab). Ini bukan sekadar leaderboard biasa. QIMMA hadir untuk membersihkan “sampah” di dunia evaluasi LLM berbahasa Arab, memastikan bahwa ketika sebuah model disebut “cerdas”, itu memang benar-benar cerdas, bukan cuma kebetulan.
🔍 Masalahnya: Evaluasi NLP Arab Terfragmentasi dan Penuh 'Kecurangan'
Bayangkan Anda menyuruh asisten rumah tangga (AI) Anda untuk membeli bumbu dapur. Tapi karena dia hanya dilatih dengan daftar belanjaan bahasa Inggris yang diterjemahkan Google Translate, dia malah pulang membawa sabun cuci piring. Ini persis seperti yang terjadi di dunia evaluasi NLP Arab saat ini: terfragmentasi, kurang validasi, dan sering salah paham karena perbedaan budaya dan dialek.
- Masalah Terjemahan: Banyak benchmark bahasa Arab yang sebenarnya cuma terjemahan asal-asalan dari bahasa Inggris. Akibatnya? Pertanyaan jadi canggung, tidak relevan secara budaya, dan bikin AI ikut-ikutan “kurang piknik”.
- Absennya Validasi Kualitas: Bahkan benchmark asli bahasa Arab pun sering dirilis tanpa pemeriksaan kualitas yang ketat. Inkonsistensi anotasi, jawaban yang salah, eror encoding, hingga bias budaya dalam label kebenaran adalah pemandangan umum. Robot mana yang bisa pintar kalau gurunya saja ngaco?
- Lubang Reproduksibilitas: Skrip evaluasi dan hasil per-sampel jarang dipublikasikan. Ini seperti Anda minta laporan keuangan, tapi akuntan AI Anda cuma kasih angka total tanpa detail, bikin Anda tidak bisa mengaudit atau belajar dari kesalahannya.
QIMMA muncul sebagai Majikan sejati di tengah kekacauan ini. Lihat perbandingannya:
| Leaderboard | Open Source | Native Arabic | Quality Validation | Code Eval | Public Outputs |
|---|---|---|---|---|---|
| OALL v1 | ✅ | Mixed | ❌ | ❌ | ✅ |
| OALL v2 | ✅ | Mostly | ❌ | ❌ | ✅ |
| BALSAM | Partial | 50% | ❌ | ❌ | ❌ |
| AraGen | ✅ | 100% | ❌ | ❌ | ❌ |
| SILMA ABL | ✅ | 100% | ✅ | ❌ | ✅ |
| ILMAAM | Partial | 100% | ✅ | ❌ | ❌ |
| HELM Arabic | ✅ | Mixed | ❌ | ❌ | ✅ |
| ⛰ QIMMA | ✅ | 99% | ✅ | ✅ | ✅ |
QIMMA adalah satu-satunya platform yang menggabungkan kelima properti ini: open source, konten mayoritas asli Arab, validasi kualitas sistematis, evaluasi kode, dan output inferensi per-sampel yang transparan. Sebuah standar baru untuk para Majikan yang ingin robotnya tidak cuma pamer, tapi juga bekerja benar.
⛰ Apa Saja yang Ada di Dalam QIMMA?
QIMMA mengumpulkan 109 sub-set dari 14 benchmark sumber menjadi sebuah rangkaian evaluasi terpadu berisi lebih dari 52.000 sampel, mencakup 7 domain:
| Domain | Benchmarks | Task Types |
|---|---|---|
| Cultural | AraDiCE-Culture, ArabCulture, PalmX | MCQ |
| STEM | ArabicMMLU, GAT, 3LM STEM | MCQ |
| Legal | ArabLegalQA, MizanQA | MCQ, QA |
| Medical | MedArabiQ, MedAraBench | MCQ, QA |
| Safety | AraTrust | MCQ |
| Poetry & Literature | FannOrFlop | QA |
| Coding | 3LM HumanEval+, 3LM MBPP+ | Code |
Beberapa hal yang perlu Majikan perhatikan:
- 99% Konten Asli Bahasa Arab: Ini memastikan AI diuji pada bahasa aslinya, bukan versi terjemahan yang sering bikin AI “salah paham”.
- Leaderboard Arab Pertama dengan Evaluasi Kode: QIMMA mengintegrasikan versi adaptasi HumanEval+ dan MBPP+ berbahasa Arab, sehingga AI bisa diuji kemampuan ngoding-nya dengan perintah berbahasa Arab. Karena Majikan yang baik tahu, robot cerdas harus bisa semua, termasuk ngoding!
- Keragaman Domain dan Tugas: QIMMA menilai kompetensi dunia nyata termasuk pendidikan, tata kelola, kesehatan, ekspresi kreatif, dan pengembangan perangkat lunak.
🔬 Pipeline Validasi Kualitas: Ketika Robot Diuji Ulang oleh Robot dan Manusia
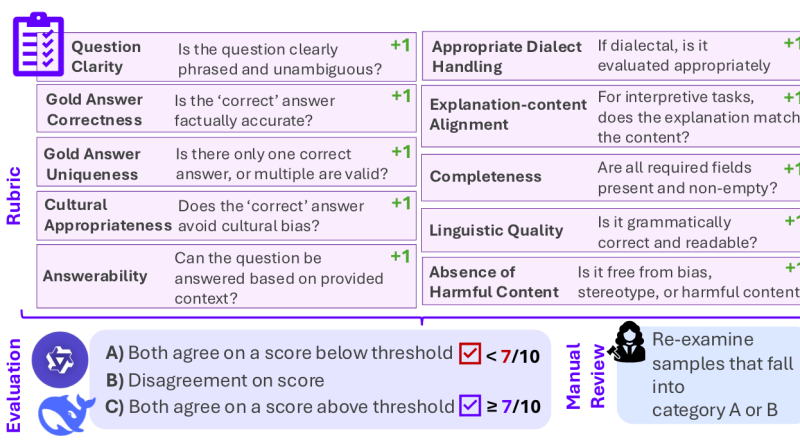
Inilah jantung metodologi QIMMA. Sebelum satu pun model AI dijalankan, TII menerapkan pipeline validasi multi-tahap pada setiap sampel di setiap benchmark. Ini seperti memasak; Majikan tidak akan menyajikan hidangan tanpa mencicipinya dulu, kan?
Stage 1: Multi-Model Automated Assessment
Setiap sampel dievaluasi secara independen oleh dua LLM paling “pintar” saat ini:
- Qwen3-235B-A22B-Instruct
- DeepSeek-V3-671B
Mereka dipilih karena kemampuan bahasa Arab yang kuat namun dengan komposisi data pelatihan yang berbeda. Tujuannya, agar hasil gabungan mereka lebih “valid” daripada hanya mengandalkan satu robot saja. Setiap model memberikan skor berdasarkan rubrik 10 poin. Jika salah satu model memberikan skor di bawah 7/10, sampel tersebut dianggap bermasalah dan diteruskan ke tahap berikutnya.

Stage 2: Human Annotation and Review
Sampel yang “di-flag” pada Tahap 1, entah oleh satu atau kedua robot, akan ditinjau oleh penutur asli bahasa Arab yang memiliki pemahaman mendalam tentang budaya dan dialek. Di sinilah peran Majikan manusia tidak tergantikan:
- Kontekstualisasi budaya dan variasi regional.
- Nuansa dialek yang hanya bisa dipahami manusia.
- Interpretasi subjektif yang sering dilewatkan AI.
- Masalah kualitas halus yang mungkin tidak terdeteksi oleh robot.
Untuk konten yang sensitif budaya, beberapa perspektif dipertimbangkan, karena “kebenaran” bisa sangat bervariasi di berbagai wilayah Arab. Ingat, robot bisa rajin, tapi akal manusia tetap yang paling jenius!
⚠️ Yang Kami Temukan: Masalah Kualitas Sistematis (Ternyata Robot Butuh Sekolah Lagi!)
Proses validasi ini mengungkap masalah kualitas yang berulang di berbagai benchmark, bukan sekadar kesalahan terisolasi, melainkan pola sistematis yang menunjukkan celah dalam cara benchmark dibangun. Ini membuktikan, seberapa pun canggihnya AI, ia tetap perlu bimbingan Majikan yang teliti.
Berdasarkan Angka
| Benchmark | Total Samples | Discarded | Discard Rate |
|---|---|---|---|
| ArabicMMLU | 14,163 | 436 | 3.1% |
| MizanQA | 1,769 | 41 | 2.3% |
| PalmX | 3,001 | 25 | 0.8% |
| MedAraBench | 4,960 | 33 | 0.7% |
| FannOrFlop | 6,984 | 43 | 0.6% |
| ArabCulture | 3,482 | 7 | 0.2% |
| MedArabiQ | 499 | 1 | 0.2% |
| GAT | 13,986 | 1 | ~0.0% |
| 3LM STEM | 2,609 | 1 | ~0.0% |
| AraDiCE-Culture | 180 | 0 | 0.0% |
| ArabLegalQA | 79 | 0 | 0.0% |
| AraTrust | 522 | 0 | 0.0% |
ArabicMMLU menunjukkan tingkat “sampah” tertinggi, dengan 3.1% sampel harus dibuang. Ini menunjukkan bahwa bahkan benchmark yang paling sering digunakan pun masih membutuhkan sentuhan akal Majikan.
Taksonomi Masalah yang Ditemukan
⚖️ Kualitas Jawaban
Indeks emas palsu atau tidak cocok, jawaban salah secara faktual, jawaban berupa teks mentah, atau jawaban yang hilang.
📄 Kualitas Teks & Format
Teks rusak atau tidak terbaca, kesalahan ejaan dan tata bahasa, serta sampel yang duplikat.
💬 Sensitivitas Budaya
Penguatan stereotip dan generalisasi monolitis tentang komunitas yang beragam.
🤝 Kepatuhan Jawaban Emas
Ketidaksesuaian jawaban emas dengan protokol evaluasi.
Sangat jelas, AI masih butuh sekolah etika, bahasa, dan bahkan logika dasar. Para Majikan, inilah tugas kita untuk membimbing mereka.
💻 Benchmark Kode: Ketika Robot Programmer Butuh Revisi
Untuk benchmark kode, QIMMA tidak buang sampah, melainkan memperbaiki pernyataan masalah berbahasa Arab. Ini seperti mengajari anak coding untuk memahami instruksi dengan jelas sebelum mulai menulis kode. Tingkat modifikasinya sangat mencengangkan:
| Benchmark | Total Prompts | Modified | Unchanged | Modification Rate |
|---|---|---|---|---|
| 3LM HumanEval+ | 164 | 145 | 19 | 88% |
| 3LM MBPP+ | 378 | 308 | 70 | 81% |
Hampir 90% instruksi kode harus direvisi! Ini membuktikan betapa pentingnya kejelasan instruksi dari Majikan kepada robotnya.
⚙️ Pengaturan Evaluasi: Mesin Sudah Siap, Tinggal Akal Majikan yang Mengendalikan
QIMMA menggunakan LightEval, EvalPlus, dan FannOrFlop sebagai kerangka evaluasinya, menjamin konsistensi dan reproduktifitas. Berbagai metrik digunakan sesuai jenis tugas, mulai dari Akurasi Log-Likelihood hingga Pass@1 untuk evaluasi kode.
Prompt juga distandarisasi dengan enam jenis template, semua dalam bahasa Arab, termasuk untuk pertanyaan pilihan ganda kontekstual (MCQ-C) hingga pertanyaan isian (QA-F).
🏆 Hasil Leaderboard: Siapa Robot Paling Pintar Setelah Disuruh Sekolah Lagi?
QIMMA mengevaluasi 46 model open-source, dari model khusus Arab hingga multibahasa. Inilah hasilnya:
| Model | Avg | Cultural | STEM | Legal | Medical | Safety | Coding | Poetry |
|---|---|---|---|---|---|---|---|---|
| Qwen2.5-72B-Instruct | 65.75 | 72.94 | 72.41 | 67.11 | 47.13 | 88.51 | 54.98 | 57.51 |
| Qwen2.5-14B-Instruct | 56.98 | 61.59 | 58.53 | 63.24 | 37.79 | 81.42 | 48.53 | 56.87 |
| Qwen3-8B | 39.38 | 35.37 | 31.39 | 52.97 | 30.02 | 52.68 | 37.50 | 57.47 |
| Qwen3.5-9B | 56.28 | 59.39 | 61.18 | 54.95 | 40.10 | 77.97 | 49.31 | 59.57 |
| Qwen3.5-27B | 59.70 | 60.61 | 65.49 | 59.67 | 38.92 | 86.59 | 63.39 | 47.03 |
| Jais-2-70B-Chat | 65.81 | 81.95 | 73.64 | 70.69 | 51.84 | 90.23 | 31.58 | 56.13 |
| Jais-2-8B-Chat | 57.89 | 71.18 | 65.94 | 65.54 | 42.99 | 87.55 | 21.30 | 51.94 |
| Llama-3.3-70B-Instruct | 63.96 | 77.74 | 70.33 | 65.72 | 55.56 | 85.63 | 49.30 | 24.43 |
| AceGPT-v2-32B-Chat | 61.14 | 76.97 | 70.51 | 67.68 | 48.64 | 86.97 | 39.14 | 15.56 |
| Yehia-7B-preview | 57.61 | 76.02 | 59.26 | 63.06 | 39.42 | 87.36 | 24.42 | 59.64 |
| Fanar-1-9B-Instruct | 56.78 | 72.78 | 65.64 | 65.47 | 49.44 | 88.51 | 30.66 | 0.02 |
| ALLaM-7B-Instruct-preview | 56.51 | 63.86 | 67.10 | 64.53 | 42.36 | 84.10 | 25.96 | 48.48 |
| gemma-3-27b-it | 60.75 | 58.84 | 68.64 | 66.92 | 42.94 | 85.44 | 51.57 | 59.74 |
| gpt-oss-20b | 32.10 | 28.35 | 23.11 | 52.46 | 29.29 | 32.38 | 41.92 | 15.34 |
Beberapa hal yang layak Majikan garis bawahi:
- Jais-2-70B-Chat memimpin secara keseluruhan, menunjukkan bahwa model yang dilatih khusus bahasa Arab masih bisa menjadi yang teratas.
- Qwen2.5-72B-Instruct membuntuti ketat, menunjukkan bahwa model multibahasa umum pun sangat kompetitif.
- Llama-3.3-70B-Instruct mendominasi di domain Medis, sementara Qwen3.5-27B unggul di bidang Coding. Ini bukti bahwa AI punya spesialisasi.
- Domain Coding tetap menjadi yang tersulit bagi model khusus Arab. Mayoritas model khusus Arab mencetak di bawah 35% dalam Coding. Ini mengindikasikan bahwa masih banyak “PR” bagi robot-robot ini. Jangan sampai Anda, sebagai Majikan, mengandalkan robot yang belum lulus ujian coding!
Baca juga artikel menarik lainnya di kategori Sidang Bot.
Hubungan Ukuran dan Kinerja: Besar Belum Tentu Pintar
Ada korelasi antara ukuran model dan kinerja, tapi tidak selalu sempurna. Contohnya, beberapa model khusus Arab yang lebih kecil (seperti Fanar-1-9B, ALLaM-7B) justru mengungguli model multibahasa yang jauh lebih besar di domain tertentu. Ini seperti asisten rumah tangga yang kecil tapi sangat efisien di dapur, mengalahkan asisten besar yang cuma jago pamer otot.
Hal ini mirip dengan apa yang IBM temukan dalam benchmark mereka, bahwa klaim di atas kertas seringkali berbeda jauh dengan realita di lapangan. Untuk mengetahui lebih lanjut tentang bagaimana AI “hebat di kertas, lemah di lapangan”, Anda bisa membaca AI Agen Industri: Hebat di Kertas, Lemah di Lapangan?.
🌟 Apa yang Membuat QIMMA Berbeda?
Singkatnya, QIMMA adalah leaderboard yang berani “kotor-kotoran” memeriksa data, bukan cuma pamer hasil akhir. Filosofi quality-first, validasi multi-model dan manusia, konten 99% asli Arab, evaluasi kode, serta transparansi penuh adalah poin utamanya. Ini memastikan robot yang Anda pekerjakan benar-benar bisa diandalkan. Ini juga penting agar kita tidak terjebak dalam skandal “contekan” AI yang bikin akal sehat Majikan dipertanyakan.
Jika Anda ingin menguasai bagaimana cara memberi perintah yang “tidak bisa dibantah” dan memastikan AI Anda bekerja sesuai standar Majikan, mungkin sudah saatnya Anda melirik kursus AI Master. Kendalikan AI agar kamu tetap menjadi Majikan, bukan babu teknologi.
Penutup: Robot Hanya Alat, Kaulah Majikan yang Punya Akal
QIMMA membuktikan satu hal: seberapa pun canggihnya algoritma dan seberapa besar data yang diproses, AI hanyalah alat. Kecerdasannya sangat bergantung pada kualitas data yang diberikan dan ketelitian Majikan dalam mengujinya. Tanpa akal sehat, ketelitian, dan validasi dari manusia, robot akan terus “halusinasi” dan memberikan hasil yang tidak bisa dipercaya. Ingat, tombol “on” dan “off” AI ada di tangan Anda, bukan sebaliknya.
Oh, dan jangan lupa, mengecek kualitas kasur sebelum tidur itu penting. Karena robot secanggih apapun, tidak akan tahu cara memperbaiki punggung Anda yang pegal.
Sumber Berita:
Artikel ini dirangkum dari sumber asli di “QIMMA قِمّة ⛰: A Quality-First Arabic LLM Leaderboard”
Gambar oleh: Technology Innovation Institute via Hugging Face